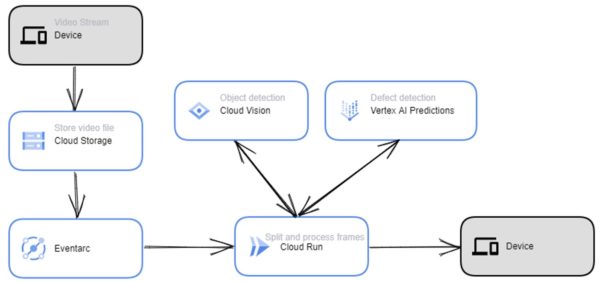
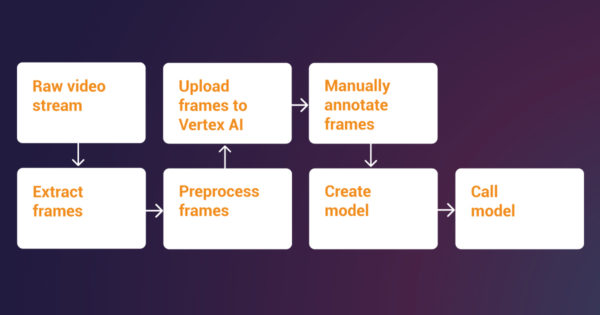
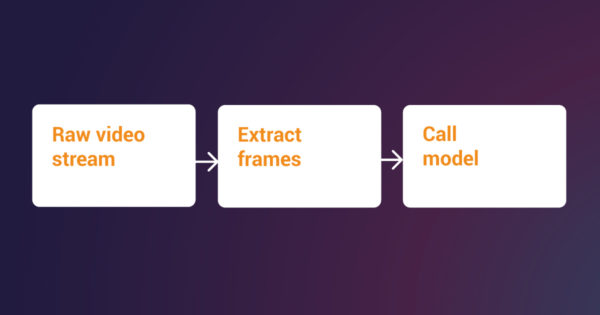
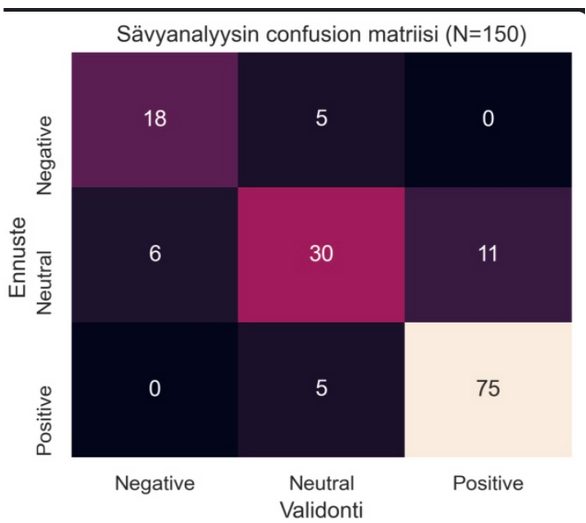
Codento Community Blog: Six Pitfalls of Digitalization – and How to Avoid Them
By Codento consultants
Introduction
We at Codento have been working hard over the last few months on various digitization projects as consultants and have faced dozens of different customer situations. At the same time, we have stopped to see how much of the same pitfalls are encountered at these sites that could have been avoided in advance.
The life mission of a consulting firm like Codento is likely to provide a two-pronged vision for our clients: to replicate the successes generally observed and, on the other hand, to avoid pitfalls.
Drifting into avoidable repetitive pitfalls always causes a lot of disappointment and frustration, so we stopped against the entire Codento team of consultants to reflect and put together our own ideas, especially to avoid these pitfalls.
A lively and multifaceted communal exchange of ideas was born, which, based on our own experience and vision, was condensed into six root causes and wholes:
- Let’s start by solving the wrong problem
- Remaining bound to existing applications and infrastructure
- Being stuck with the current operating models and processes
- The potential of new cloud technologies is not being optimally exploited
- Data is not sufficiently utilized in business
- The utilization of machine learning and artificial intelligence does not lead to a competitive advantage
Next, we will go through this interesting dialogue with Codento consultants.
Pitfall 1: Let’s start by solving the originally wrong problem
How many Design Sprints and MVPs in the world have been implemented to create new solutions in such a way that the original problem setting and customer needs were based on false assumptions or otherwise incomplete?
Or that many problems more valuable to the business have remained unresolved when they are left in the backlog? Choosing a technology between a manufactured product or custom software, for example, is often the easiest step.
There is nothing wrong with the Design Sprint or Minimum Viable Product methodology per se: they are very well suited to uncertainty and an experimental approach and to avoid unnecessary productive work, but there is certainly room for improvement in what problems they apply to.
Veera also recalls one situation: “Let’s start solving the problem in an MVP-minded way without thinking very far about how the app should work in different use cases. The application can become a collection of different special cases and the connecting factor between them is missing. Later, major renovations may be required when the original architecture or data model does not go far enough. ”
Markku smoothly lists the typical problems associated with the conceptualization and MVP phase: “A certain rigidity in rapid and continuous experimentation, a tendency to perfection, a misunderstanding of the end customer, the wrong technology or operating model.”
“My own solution is always to reduce the definition of a problem to such a small sub-problem that it is faster to solve and more effective to learn. At the same time, the positive mood grows when something visible is always achieved, ”adds Anthony.
Toni sees three essential steps as a solution: “A lot of different problem candidates are needed. One of them will be selected for clarification on the basis of common criteria. Work on problem definition both extensively and deeply. Only then should you go to Design Sprint. ”
Pitfall 2: Trapped with existing applications and infrastructure
It’s easy in “greenfield” projects where the “table is clean,” but what to do when the dusty application and IT environment of the years is an obstacle to ambitious digital vision?
Olli-Pekka starts: “Software is not ready until it is taken out of production. Until then, more or less money will sink in, which would be nice to get back, either in terms of working time saved, or just as income. If the systems in production are not kept on track, then the costs that will sink into them are guaranteed to surpass the benefits sooner or later. This is due to inflation and the exponential development of technology. ”
“A really old system that supports a company’s business and is virtually impossible to replace,” continues Jari T. “The low turnover and technology age of it means that the system is not worth replacing. The system will be shut down as soon as the last parts of the business have been phased out. ”
“A monolithic system comes to mind that cannot be renewed part by part. Renewing the entire system would be too much of a cost, ”adds Veera.
Olli-Pekka outlines three different situations: “Depending on the user base, the pressures for modernization are different, but the need for it will not disappear at any stage. Let’s take a few examples.
Consumer products – There is no market for antiques in this industry unless your business is based on the sale of NFTs from Doom’s original source code, and even then. Or when was the last time you admired Win-XP CDs on a store shelf?
Business products – a slightly more complicated case. The point here is that in order for the system you use to be relevant to your business, it needs to play kindly with other systems your organization uses. Otherwise, a replacement will be drawn for it, because manual steps in the process are both expensive and error-prone. However, there is no problem if no one updates their products. I would not lull myself into this.
Internal use – no need to modernize? All you have to do here is train yourself to replace the new ones, because no one else is doing it to your stack anymore. Also, remember to hope that not everyone who manages to entice you into this technological impasse will come up with a peek over the fence. And also remember to set aside a little extra funds for maintenance contracts, as outside vendors may raise their prices when the number of users for their sunset products drops. ”
A few concepts immediately came to mind by Iiro: “Path dependency and Sunk cost fallacy. Could one write own blog about both of them? ”
“What are the reasons or inconveniences for different studies?” ask Sami and Marika.
“I have at least remembered the budgetary challenges, the complexity of the environments, the lack of integration capacity, data security and legislation. So what would be the solution? ”Anthony answers at the same time.
Olli-Pekka’s three ideas emerge quickly: “Map your system – you should also use external pairs of eyes for this, because they know how to identify even the details that your own eye is already used to. An external expert can also ask the right questions and fish for the answers. Plan your route out of the trap – less often you should rush blindly in every direction at the same time. It is enough to pierce the opening where the fence is weakest. From here you can then start expanding and building new pastures at a pace that suits you. Invest in know-how – the easiest way to make a hole in a fence is with the right tools. And a skilled worker will pierce the opening so that it will continue to be easy to pass through without tearing his clothes. It is not worth lulling yourself to find this factor inside the house, because if that were the case, that opening would already be in it. Or the process rots. In any case, help is needed. ”
Pitfall 3: Remaining captive to current policies
“Which is the bigger obstacle in the end: infrastructure and applications or our own operating models and lack of capacity for change?”, Tommi ponders.
“I would be leaning towards operating models myself,” Samuel sees. “I am strongly reminded of the silo between business and IT, the high level of risk aversion, the lack of resilience, the vagueness of the guiding digital vision, and the lack of vision.”
Veera adds, “Let’s start modeling old processes as they are for a new application, instead of thinking about how to change the processes and benefit from better processes at the same time.”
Elmo immediately lists a few practical examples: “Word + Sharepoint documentation is limiting because “this is always the case”. Resistance to change means that modern practices and the latest tools cannot be used, thereby excluding some of the contribution from being made. This limits the user base, as it is not possible to use the organisation’s cross-border expertise. ”
Anne continues: “Excel + word documentation models result in information that is widespread and difficult to maintain. The flow of information by e-mail. The biggest obstacle is culture and the way we do it, not the technology itself. ”
“What should I do and where can I get motivation?” Perttu ponders and continues with the proposed solution: “Small profits quickly – low-hanging-fruits should be picked. The longer the inefficient operation lasts, the more expensive it is to get out of there. Sunk Cost Fallacy could be loosely combined with this. ”
“There are limitless areas to improve.” Markku opens a range of options: “Business collaboration, product management, application development, DevOps, testing, integration, outsourcing, further development, management, resourcing, subcontracting, tools, processes, documentation, metrics. There is no need to be world-class in everything, but it is good to improve the area or areas that have the greatest impact with optimal investment. ”
Pitfall 4: The potential of new cloud technologies is not being exploited
Google Cloud, Azure, AWS or multi-cloud? Is this the most important question?
Markku answers: “I don’t think so. The indicators of financial control move cloud costs away from the depreciation side directly higher up the lines of the income statement, and the target setting of many companies does not bend to this, although in reality it would have a much positive effect on cash flow in the long run. ”
Sanna comes to mind a few new situations: “Choose the technology that is believed to best suit your needs. This is because there is not enough comprehensive knowledge and experience about existing technologies and their potential. Therefore, one may end up with a situation where a lot of logic and features have already been built on top of the chosen technology when it is found that another model would have been better suited to the use case. Real-life experience: “With these functions, this can be done quickly”, two years later: “Why wasn’t the IoT hub chosen?”
Perttu emphasizes: “The use of digital platforms at work (eg drive, meet, teams, etc.) can be found closer to everyday business than in the cold and technical core of cloud technology. Especially as the public debate has recently revolved around the guidelines of a few big companies instructing employees to return to local work. ”
Perttu continues: “Compared to this, the services offered by digital platforms make operations more agile and enable a wider range of lifestyles, as well as streamlining business operations. It must be remembered, of course, that physical encounters are also important to people, but it could be assumed that experts in any field are best at defining effective ways of working themselves. Win-win, right? ”
So what’s the solution?
“I think the most important thing is that the features to be deployed in the cloud capabilities are adapted to the selected short- and long-term use cases,” concludes Markku.
Pitfall 5: Data is not sufficiently utilized in business
Aren’t there just companies that can avoid having the bulk of their data in good possession and integrity? But what are the different challenges involved?
Aleksi explains: “The practical obstacle to the wider use of data in an organization is quite often the poor visibility of the available data. There may be many hidden data sets whose existence is known to only a couple of people. These may only be found by chance by talking to the right people.
Another similar problem is that for some data sets, the content, structure, origin or mode of origin of the data is no longer really known – and there is little documentation of it. ”
Aleksi continues, “An overly absolute and early-applied business case approach prevents data from being exploited in experiments and development involving a“ research aspect ”. This is the case, for example, in many new cases of machine learning: it is not clear in advance what can be expected, or even if anything usable can be achieved. Thus, such early action is difficult to justify using a normal business case.
It could be better to assess the potential benefits that the approach could have if successful. If these benefits are large enough, you can start experimenting, look at the situation constantly, and snatch ideas that turn out to be bad quickly. The time of the business case may be later. ”
Pitfall 6: The use of machine learning and artificial intelligence will not lead to a competitive advantage
It seems to be fashionable in modern times for a business manager to attend various machine learning courses and a varying number of experiments are underway in organizations. However, it is not very far yet, is it?
Aleksi opens his experiences: “Over time, the current“ traditional ”approach has been filed quite well, and there is very little potential for improvement. The first experiments in machine learning do not produce a better result than at present, so it is decided to stop examining and developing them. In many cases, however, the situation may be that the potential of the current operating model has been almost completely exhausted over time, while on the machine learning side the potential for improvement would reach a much higher level. It is as if we are locked in the current way only because the first attempts did not immediately bring about improvement. ”
Anthony summarizes the challenges into three components: “Business value is unclear, data is not available and there is not enough expertise to utilize machine learning.”
Jari R. wants to promote his own previous speech at the spring business-oriented online machine learning event. “If I remember correctly, I have compiled a list of as many as ten pitfalls suitable for this topic. In this event material, they are easy to read:
- The specific business problem is not properly defined.
- No target is defined for model reliability or the target is unrealistic.
- The choice of data sources is left to data scientists and engineers and the expertise of the business area’s experts is not utilized.
- The ML project is carried out exclusively by the IT department itself. Experts from the business area will not be involved in the project.
- The data needed to build and utilize the model is considered fragmented across different systems, and cloud platform data solutions are not utilized.
- The retraining of the model in the cloud platform is not taken into account already in the development phase.
- The most fashionable algorithms are chosen for the model. The appropriateness of the algorithms is not considered.
- The root causes of the errors made by the model are not analyzed but blindly rely on statistical accuracy parameters.
- The model will be built to run on Data Scientist’s own machine and its portability to the cloud platform will not be considered during the development phase.
- The ability of the model to analyze real business data is not systematically monitored and the model is not retrained. ”
This would serve as a good example of the thoroughness of our data scientists. It is easy to agree with that list and believe that we at Codento have a vision for avoiding pitfalls in this area as well.
Summary – Avoid pitfalls in a timely manner
To prevent you from falling into the pitfalls, Codento consultants have promised to offer two-hour free workshops to willing organizations, always focusing on one of these pitfalls at a time:
- Digital Value Workshop: Clarified and understandable business problem to be solved in the concept phase
- Application Renewal Workshop: A prioritized roadmap for modernizing applications
- Process Workshop: Identifying potential policy challenges for the evaluation phase
- Cloud Architecture Workshop: Helps identify concrete steps toward high-quality cloud architecture and its further development
- Data Architecture Workshop: Preliminary current situation of data architecture and potential developments for further design
- Artificial Intelligence Workshop: Prioritized use case descriptions for more detailed planning from a business feasibility perspective
Ask us for more information and we will make an appointment for August, so the autumn will start comfortably, avoiding the pitfalls.
















 Run.
Run. mer satisfaction, and increased revenue.
mer satisfaction, and increased revenue. that Codento was awarded with the Partner Impact 2023 Recognition in Finland by Google Cloud Nordic team. Codento received praise for deep expertise in Google Cloud services and market impact, impressive NPS score, and
that Codento was awarded with the Partner Impact 2023 Recognition in Finland by Google Cloud Nordic team. Codento received praise for deep expertise in Google Cloud services and market impact, impressive NPS score, and