
Why do data professionals prefer Google Cloud?
And why should you care?
Author: Juhani Takkunen, Data Engineer, Codento
Your data engineers have the challenging job of staying one step ahead of data scientists, ensuring that data is available, trustworthy and up-to-date when needed – even if it’s not needed right now. This way, your organization’s data remains ready to be turned into actionable business value and insights, whether for ad-hoc reports or data scientists’ deep-dive investigations.
Makes sense, right? So why isn’t everyone doing this already? The simple answer: costs.
The data platform costs can be divided into infrastructure and engineering costs, which both are quite predictable: larger data volumes require more storage and compute performance and more data sources increase the need for data engineering. While storage and platform costs have generally come down with serverless solutions especially, the data engineering effort and costs can still be significant. This unfortunately often leads to valuable data remaining untapped.
In this post, I will explore why Google Cloud, particularly its analytics database BigQuery, is a top choice for data engineers and how it can help organizations overcome common data challenges. I will show how technical tools affect design decisions and why data professionals prefer certain tools and design patterns over others.
The data engineer’s choice: Google Cloud
Key features of a good data platform are security, ease of development and maintenance, and low cost. These are some of the reasons why top professionals working with vast amounts of data, such as researchers worldwide, prefer Google Cloud. According to the StackOverflow 2024 developer survey, again, some two out of three senior data engineers currently working with BigQuery or Google Cloud would want to continue using these technologies, while less than 20% would like to switch to alternatives.
Despite these statistics, many organizations still choose data tools based on what their businesspeople are accustomed to and like to use. This frequently leads to the adoption of Microsoft platforms like Azure or Power BI. While these tools are powerful in their familiarity with the business user, they may not align with the needs of data engineers who desire more flexibility and scalability. Just like the business people are allowed to determine what is the best tool for their work, so can and should the data team. Selecting the right tool for the task is vital for success, even if it means adhering to a multi-cloud environment.
Data storage: BigQuery
Google Cloud suite of services includes an incredibly scalable and cost effective serverless analytics database called BigQuery. BigQuery offers highly scalable data storage that developers can access and modify by using familiar languages such as SQL or Python, regardless of the developer’s earlier background. Not all serverless solutions come with such benefits, as for example Azure Synapse Serverless does not directly support modifying data using SQL-DML statements (INSERT, UPDATE, DELETE).
BigQuery offers benefits like high availability, unlimited storage, and scalability. Its pricing model, based on data processed rather than stored, makes it a cost-effective solution for large datasets. As storage and operations are billed separately, there is no need to ever pause the service. BigQuery can also easily be connected to any modern BI-system, such as Looker, PowerBI or Qlik.
Pricing model based on data processed, not data stored.
The most pressing challenge for many organizations is the vast amount of unstructured data, such as text, pdfs and images, that remains untapped, as many data platforms or data platform substitutes like Excel struggle to make this data accessible for analytics.
BigQuery is optimized for machine learning (ML) tasks. Google Cloud’s acceptance among data and AI enthusiasts is evident as 70% of generative AI startups rely on Google Cloud’s AI Capabilities. This staggering number proves that the people who bet their livelihoods on data and generative AI find Google Cloud’s offering and technology most appealing. BigQuery ensures data accessibility across the organization with strict access controls, empowering employees while maintaining security. It also integrates seamlessly with other Google Cloud services, creating comprehensive data pipelines.
In early 2024, the Enterprise Strategy Group (ESG) compared the cost and features of four major cloud data warehouse solutions: BigQuery, AWS Redshift, Snowflake, and Azure Databricks SQL Serverless. They interviewed users and studied cases to build a realistic model of the three-year total cost of ownership (TCO) of these data warehouse solutions. They found that BigQuery could reduce TCO by up to 54%, offering easier operation, better flexibility, and built-in compatibility with other cloud services.
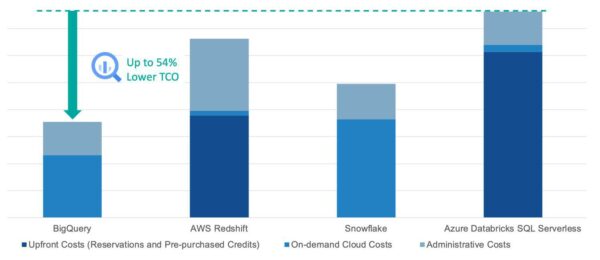
BigQuery eliminates the need to manage, monitor, and secure data warehouse infrastructure, allowing teams to focus on using insights instead of managing the process. Unlike other solutions, BigQuery is fully managed, meaning there are no physical or virtual servers to handle. It optimizes storage automatically and supports AI and machine learning work.
Data pipelines: Dataflow and Dataproc
Data pipelines often start from a simple task: load data from the source and store it in a database. One could imagine that such a repeatable, simple task can be solved using something simple like a low-/no-code solution. Unfortunately, in our experience, the data sources and scenarios are so versatile that eventually each ETL (Extract-Transform-Load) tool requires at least some custom code. Exceptions are often related to authentication, data parsing, dynamic mapping, retry-mechanisms or error handling. As simple tasks grow into more complex business problems, the simplest development tools may start to restrict the data engineers and especially maintaining the hacky solutions can be a real challenge.
Based on our customer examples, data engineers typically prefer tooling that allows multiple developers to work simultaneously. Developers need to be able to run individual pipelines locally or in a sandbox environment, reuse code with functions, and deploy code using pull-requests and version control. The last part often turns out to be the most challenging, since a successful pull-request-review requires the reviewer to be able to both review and validate the change.
The main ETL tools in Google Cloud are Dataflow and Dataproc, both offer serverless ETL solutions. Dataflow and Dataproc are based on the Apache open source projects Beam and Spark, respectively. With these tools, data engineers can write reusable and testable code with popular programming languages such as Python and Java.
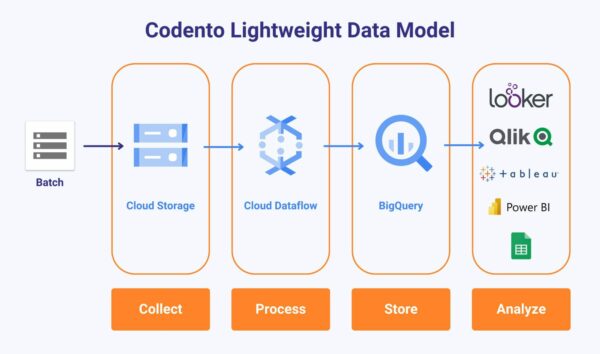
A lightweight, scalable data model – as a Service, if you will
BigQuery’s cost-effective pricing model and serverless nature make it an efficient and scalable tool that allows data engineers to focus on extracting insights rather than maintaining systems or managing costs. Codento, in turn, is the leading Nordic Google Cloud-focused software integrator. Our extensive Google Cloud data platform proficiency has proven that a lightweight data model built on serverless technologies like BigQuery and Python can effectively harness data from diverse sources.
Based on our earlier hands-on experiences with customers like Nordic e-commerce leader BHG and electric car charging solution pioneer, Plugit, Codento has now built an opinionated data model for our customers. Our new turnkey solution, Lightweight Data Model is scalable in terms of performance and cost, making it suitable for organizations of all sizes. The setup is pre-configured, making it ready-to-use with minimal configuration effort, typically within eight weeks from customer’s decision to proceed.
This new Data Model solution can be implemented in your existing Google Cloud environment or in a new environment, or it can also be offered as software as a Service. In the latter case, Codento manages the data platform for you in our environment. Such a turn-key solution allows you to concentrate on your business and, if you will, to continue using your existing tools on the side of the new data model.
Key takeaways:
- Google Cloud’s BigQuery offers scalable, serverless data storage for datasets of any size.
- According to surveys, data professionals prefer to work with Google Cloud and BigQuery.
- Google Cloud services scale effortlessly with future requirements, such as data volume, machine learning tasks, automated testing and quality controls.

About the author:
Juhani Takkunen is an experienced data engineer and Python wizard. He likes building working solutions where data flows efficiently.
Stay tuned for more detailed information and examples of the use cases! If you need more information about specific scenarios or want to schedule a free workshop to explore the opportunities in your organization, feel free to reach out to us.
