
Business-driven Machine Learner with Google Cloud: Multilingual Customer Feedback Classifier
Author: Jari Rinta-aho, Codento
At Codento, we have rapidly expanded our services to demanding implementations and services for data and machine learning. When discussing with our customers, the following business goals and expectations have often come to the fore:
- Disclosure of hidden regularities in data
- Automation of analysis
- Minimizing human error
- New business models and opportunities
- Improving and safeguarding competitiveness
- Processing of multidimensional and versatile data material
In this blog post, I will go through the lessons from our recent customer case.
Competitive advantage from deep understanding customer feedback
A very concrete business need arose this spring for a Finnish B-to-C player: huge amounts of customer feedback data come, but how to utilize feedback intelligently in decision-making to make the right business decisions.
Codento recommended the use of machine learning
Codento’s recommendation was to take advantage of the challenging machine learning approach and Google Cloud off-the-shelf features to get the customer feedback classifier ready by the week.
The goal was to automatically classify short Customer Feedback into three baskets: Positive, Neutral, and Negative. Customer feedback was mainly short Finnish texts. However, there were also a few texts written in Swedish and English. The classifier must therefore also be able to recognize the language of the source text automatically.
Can you really expect results in a week?
At the same time, the project was tight on schedule and ambitious. There was no time to waste in the project, but in practice the results had to be obtained on the first try. Codento therefore decided to make the most of the ready-made cognitive services.
Google Cloud plays a key role
It was decided to implement the classifier by combining two ready-made tools found in the Google Cloud Platform: Translate API and Natural Language API. The purpose was to mechanically translate the texts into English and determine their tone. Because the Translate API is able to automatically detect the source language from about a hundred different languages, the tool met the requirements, at least on paper.
Were the results useful?
Random sampling and craftsmanship were used to validate the results. From the existing data, 150 texts were selected at random for the validation of the classifier. First, these texts were sorted by hand into three categories: positive, neutral, and negative. After that, the same classification was made with the tool we developed. In the end, the results of the tool and the craft were compared.
What was achieved?
The tool and the analyzer agreed on about 80% of the feedback. There was no contrary view. The validation results were pooled into a confusion matrix.
The numbers 18, 30, and 75 on the diagonal of the image confusion matrix describe the feedback in which the Validator and the tool agreed on the tone of the feedback. A total of 11 feedbacks were those in which Validator considered the tone positive but the tool neutral.
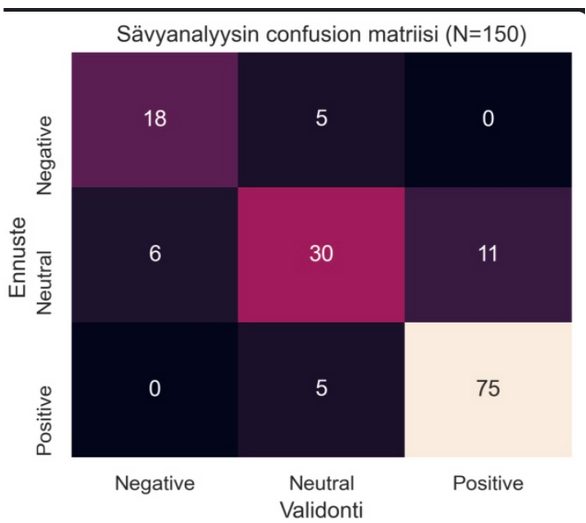
The most significant factor that explains the different interpretation made by the tool is the cultural relevance of the wording of the customer feedback, and when a Finn says “No complaining”, he praises.
Heard from an American, this is neutral feedback. This cultural difference alone is sufficient to explain why the largest single error group was “positive in the view of the validator, neutral in the view of the tool.” Otherwise, the error is explained by the difficulty of distinguishing between borderline cases. It is impossible to say unambiguously when slightly positive feedback will turn neutral and vice versa.
Utilizing the solution in business
The data-validated approach was well suited to solve the challenge and is an excellent starting point for understanding the nature of feedback in the future, developing further models for more detailed analysis, speeding up analysis and reducing manual work. The solution can also be applied to a wide range of similar situations and needs in other processes or industries.
The author of the article is Jari Rinta-aho, Senior Data Scientist & Consultant, Codento. Jari is a consultant and physicist interested in machine learning and mathematics, who has extensive experience in utilizing machine learning, e.g. nuclear technologies. He has also taught physics at the university and led international research projects.
