
Tekoäly teollisuudessa: Konenäkö laadun varmistamisessa
Kirjoittaja: Janne Flinck
Johdanto
Smart Industry -tapahtuman innoittamana päätimme aloittaa sarjan blogitekstejä, joissa käsitellään tekoälyn hyödyntämistä teollisuuden sovelluksissa. Tässä ensimmäisessä osassa käsittelemme laadunvalvonnan automatisointia konenäön avulla.
Teollisuus- ja logistiikkayritykset asettavat laadunvalvontaprosessiensa tehokkuuden ja tuottavuuden etusijalle. Viime vuosina konenäköpohjainen automaatio on noussut erittäin tehokkaaksi ratkaisuksi laatukustannusten ja vikojen vähentämiseen.
American Society of Quality arvioi, että useimmat valmistajat käyttävät 15–20 prosenttia tuloistaan ”todellisiin laatuun liittyviin kustannuksiin”. Jotkut organisaatiot nostavat toiminnassaan jopa 40 %:n laatukustannukset. Valmistuksen laatuun vaikuttavia kustannustekijöitä on kolmella eri alueella:
- Arviointikustannukset: materiaalien ja prosessien tarkastus, koko järjestelmän laatuauditoinnit, toimittajien arvioinnit
- Sisäiset vikakustannukset: resurssien tuhlausta tai virheistä huonosta suunnittelusta tai organisoinnista, valmiiden tuotteiden virheiden korjaamisesta, sisäisten menettelytapojen analyysin epäonnistumisesta
- Ulkoiset vikakustannukset: toimitettujen tuotteiden korjaukset ja huolto, takuuvaatimukset, reklamaatiot, palautukset
Tekoäly auttaa valmistajia kehittymään kaikilla näillä alueilla, minkä vuoksi johtavat yritykset ovat omaksuneet tämän. Google Cloudin (haastateltu yli 1 000 tuotantojohtajaa seitsemässä maassa vuonna 2021) tekemän tutkimuksen mukaan 39 % valmistajista käyttää tekoälyä laaduntarkastuksiin ja 35 % itse tuotantolinjan laaduntarkastuksiin.
Viisi yleisintä aluetta, joilla tekoälyä käytetään tällä hetkellä päivittäisessä toiminnassa:
- Laaduntarkastus 39 %
- Toimitusketjun hallinta 36 %
- Riskienhallinta 36 %
- Tuotteen ja/tai tuotantolinjan laaduntarkastukset 35 %
- Varastonhallinta 34 %
Lähde: Google Cloud Manufacturing Report
Konenäön avulla tuotantolinjatyöntekijät voivat vähentää toistuviin tuotetarkastuksiin kuluvaa aikaa, jolloin he voivat siirtää huomionsa monimutkaisempiin tehtäviin, kuten juurisyyanalyysiin.
Nykyaikaiset konenäkömallit ja -kehykset tarjoavat monipuolisuutta ja kustannustehokkuutta, ja erikoistuneet pilvipohjaiset palvelut AI-mallien koulutukseen ja reunalaitteiston käyttöönottoon (edge deployment) vähentävät edelleen toteutuksen monimutkaisuutta.
Ratkaisun yleiskatsaus
Tässä blogikirjoituksessa keskitymme vikojen havaitsemiseen kokoonpano- ja lajittelulinjoilla. Google Cloudin Vertex AI- ja AutoML-palveluilla toteutettu reaaliaikainen visuaalisen laadunvalvontaratkaisumme voi seurata useita kokoonpanolinjalla olevia kohteita, analysoida jokaisen kohteen ja arvioida vikojen tai vaurioiden todennäköisyyttä.
Ensimmäinen vaihe sisältää videovirran valmistelun jakamalla virran yksittäisiksi kuviksi analysointia varten. Seuraavassa vaiheessa käytetään mallia objektien ympärillä olevien rajauskehyksen (bounding box) tunnistamiseen.
Kun kohde on tunnistettu, viantunnistusjärjestelmä käsittelee kuvan leikkaamalla objektin rajauskehyksen avulla, muuttamalla sen kokoa ja lähettämällä sen viantunnistusmalliin luokittelua varten. Tulos on kuva, jossa kohde tunnistetaan rajauskehyksillä ja luokitellaan joko viaksi tai ei-vikaksi. Nopea prosessointiaika mahdollistaa reaaliaikaisen seurannan mallin ulosannin (output) avulla, automatisoiden vianhakuprosessin ja lisäten kokonaistehokkuutta.
Tässä esimerkki tämän ratkaisun Google Cloud arkkitehtuurista:
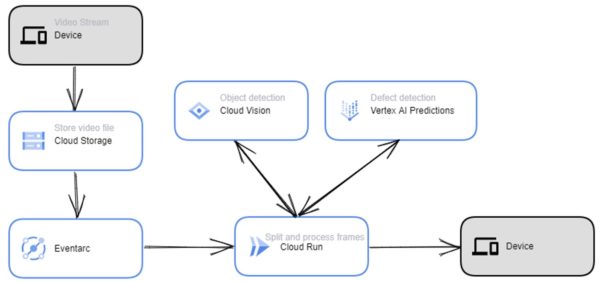
Toteutustiedot
Tässä osiossa käsittelen joitakin järjestelmän osia, pääasiassa sitä, mitä tarvitaan aloittamiseen ja mitä asioita tulee ottaa huomioon. Aineisto on itse luotu kotoa löytämistäni objekteista, mutta tätä samaa lähestymistapaa ja algoritmia voidaan käyttää missä tahansa objektissa, kunhan videon laatu on hyvä.
Tässä on esimerkkikuva videosta, jossa voimme nähdä yhden viallisen kohteen ja kolme ei-viallista objektia:

Voimme myös nähdä, että yksi kohteista on poistumassa kuvan oikealta puolelta ja toinen on tulossa kuvaan vasemmalta.
Video löytyy täältä.
Aineistojen ja mallien yleiskatsaus
Kokeessamme käytimme videota, joka simuloi tuotantohihnaa. Videolla näkyi esineitä näytöllä liikkuen vasemmalta puolelta oikealle, joista osa oli viallisia tai vaurioituneita. Koulutusaineistomme (training data) koostui noin 20 eri kohteesta, joista neljä oli viallisia.
Visuaalista laadunvalvontaa varten meidän on hyödynnettävä objektintunnistusmallia ja kuvan luokittelumallia. Kohteen tunnistusmallin rakentamiseen on kolme vaihtoehtoa:
- Kouluta Google Vertex AI AutoML:n tuottama malli
- Käytä valmiiksi rakennettua Google Cloud Vision -API:a
- Kouluta mukautettu malli
Tälle prototyypille päätimme valita molemmat vaihtoehdot 1 ja 2. Vertex AI AutoML -mallin kouluttamiseksi tarvitsemme annotoidun aineiston, jossa on rajauskehyksen koordinaatit. Aineistomme suhteellisen pienen koon vuoksi päätimme käyttää Google Cloudin datamerkintätyökalua. Suuremmille aineistoille suosittelemme kuitenkin Vertex AI -datamerkintätyökalun käyttöä.
Tätä tehtävää varten piirsimme manuaalisesti rajauskehykset jokaiselle kuvassa olevalle objektille ja annotoimme objektit. Käytimme kaiken kaikkiaan 50 kuvaa objetintunnistusmallimme kouluttamiseen, mikä on hyvin vaatimaton määrä.
Koneoppimismallit vaativat yleensä suuremman määrän näytteitä koulutukseen. Tätä blogikirjoitusta varten näytteiden määrä oli kuitenkin riittävä arvioimaan pilvipalvelun soveltuvuutta vikojen havaitsemiseen. Yleensä mitä enemmän merkittyä aineistoa voit tuoda koulutusprosessiin, sitä parempi mallistasi tulee. Toinen ilmeinen kriittinen vaatimus aineistolle on edustavat esimerkit sekä vioista että tavallisista esiintymistä.
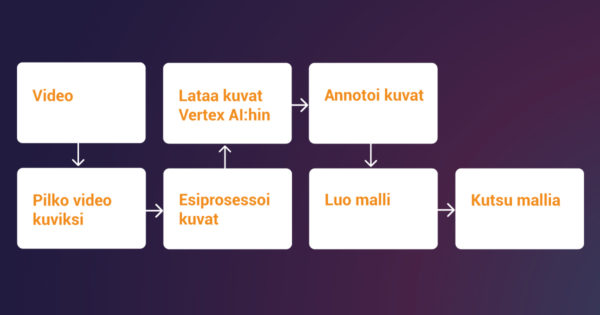
AutoML-objektien havaitsemisen ja AutoML-vian havaitsemisen ainestojen luomisen myöhemmät vaiheet sisälsivät aineiston jakamisen opetus-, validointi- ja testausalajoukoiksi. Oletusarvon mukaan Vertex AI jakaa automaattisesti 80 % kuvista harjoittelua varten, 10 % validointia varten ja 10 % testausta varten. Käytimme manuaalista jakamista datavuotojen (data leakage) välttämiseksi. Erityisesti vältämme peräkkäisten kuvien sarjoja.
AutoML-aineiston prosessi on seuraava:
Mitä tulee valmiin Google Cloud Vision -sovellusliittymän käyttämiseen objektien havaitsemiseen, aineisto-annotointia ei vaadita. Asiakaskirjastoja (client libraries) käytetään vain API:n kutsumiseen ja vastauksen käsittelemiseen, joka koostuu normalisoiduista rajauskehyksistä ja objektien nimistä. Näistä objektinimistä suodatamme sitten etsimämme kohteet. Vision API:n prosessi on seuraava:
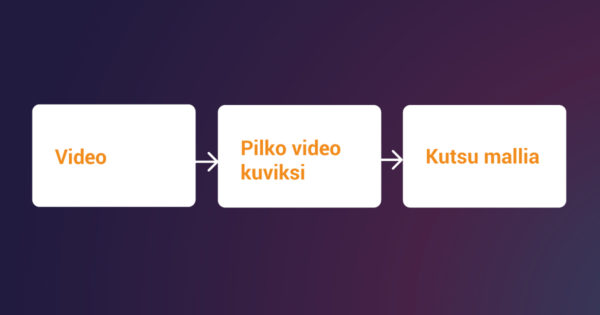
Miksi mukautettua mallia koulutettaisiin, jos Google Cloud Vision API:n käyttö on näin yksinkertaista? Ensinnäkin Vision API havaitsee yleiset objektit, joten jos on jotain hyvin erityistä, se ei ehkä ole tunnisteluettelossa. Valitettavasti näyttää siltä, että Google Cloud Vision API:n havaitsemien tunnisteiden luettelo ei ole täysin julkisesti saatavilla. Kannattaa kokeilla Google Cloud Vision API:ta ja katsoa, pystyykö se havaitsemaan kiinnostuksen kohteena olevan objektin.
Vertex AI:n dokumentaation mukaan AutoML-mallit toimivat optimaalisesti, kun vähiten esimerkkejä sisältävässä kategoriassa on vähintään 10 % esimerkeistä kategoriasta, jossa on eniten esimerkkejä. Tuotantotapauksessa on tärkeää sisällyttää suunnilleen sama määrä koulutusesimerkkejä kustakin kategoriasta.
Vaikka sinulla olisi runsaasti ainestoa yhdestä kategoriasta, on parasta jakaa dataa tasaisesti jokaiselle kategorialle. Koska ensisijainen tavoitteemme oli rakentaa prototyyppi rajoitetun aineiston avulla mallin tarkkuuden parantamisen sijaan, emme puuttuneet epätasapainoisten luokkien ongelmaan.
Objektin seuranta
Kehitimme OpenCV-kirjastoon perustuvan objektien seuranta-algoritmin vastaamaan videoskenaariomme erityisiin haasteisiin. Testaamamme seurantalaitteet olivat CSRT, KCF ja MOSSE. Seuraavat nyrkkisäännöt pätevät myös skenaariossamme:
- Käytä CSRT:tä, kun tarvitset suurempaa objektien seurantatarkkuutta ja voit sietää hitaampaa FPS-suorituskykyä
- Käytä KCF:ää, kun tarvitset nopeampaa FPS-suorituskykyä, mutta pystyt käsittelemään hieman pienempää objektien seurantatarkkuutta
- Käytä MOSSEa, kun tarvitset puhdasta nopeutta
Kohteen seurantaa varten meidän on otettava huomioon seuraavat videon ominaisuudet:
- Jokainen kuva voi sisältää yhden tai useita objekteja tai ei ollenkaan
- Uusia esineitä saattaa ilmestyä videon aikana ja vanhat esineet katoavat
- Objektit voivat olla vain osittain näkyvissä, kun ne tulevat kehykseen tai poistuvat siitä
- Samalla objektilla voi olla päällekkäisiä rajauskehyksiä
- Sama objekti on videossa useiden peräkkäisten ruutujen ajan
Koko prosessin nopeuttamiseksi lähetämme jokaisen täysin näkyvän kohteen viantunnistusmalliin vain kahdesti. Sitten laskemme mallin todennäköisyystulosten keskiarvon ja määritämme tunnisteen kyseiselle objektille pysyvästi. Näin voimme säästää sekä laskenta-aikaa että rahaa, kun emme kutsu mallin päätepistettä tarpeettomasti samalle objektille useita kertoja videon aikana.
Johtopäätökset
Tässä on ulosanti-videovirta ja rajauskehys laadunvalvontaprosessista. Sininen tarkoittaa, että kuva on havaittu, mutta sitä ei ole vielä luokiteltu, koska kuva ei ole täysin näkyvissä kehyksessä. Vihreä tarkoittaa, että vikaa ei ole havaittu ja punainen on vika:

Video löytyy täältä.
Nämä havainnot osoittavat, että on mahdollista kehittää automatisoitu visuaalinen laadunvalvontaputki mahdollisimman pienellä määrällä näytteitä. Tosimaailmassa meillä olisi pääsy paljon pidempiin videovirtoihin ja mahdollisuus laajentaa aineistoa iteratiivisesti parantaaksemme mallia, kunnes se täyttää halutut laatustandardit.
Näistä rajoituksista huolimatta pystyimme Vertex AI:n ansiosta saavuttamaan kohtuullisen laadun jo ensimmäisellä koulutuskierroksella, joka kesti vain muutaman tunnin, jopa pienellä ainestolla. Tämä korostaa esikoulutettujen mallien ja AutoML-ratkaisujen hyödyntämisen tehokkuutta ja vaikuttavuutta, sillä pystyimme saavuttamaan lupaavia tuloksia erittäin lyhyessä ajassa.

Blogin kirjoittajasta: Janne Flinck on Codenton AI & Data Lead. Janne liittyi Codentoon Accenturelta vuonna 2022. Jannella on laaja kokemus Google Cloud -teknologioista. Hänen kiinnostuksen kohteena on dataintensiivisten sovellusten ja työkalujen luominen ja arkkitehtuuri. Jannella on kolme Google Cloud -sertifikaattia.
Ota meihin yhteyttä niin keskustellaan teollisuuden tekoälyratkaisuista lisää!